|
|
This document is the fifth and final part of the introduction to TransacXML.
This document describes different ways you can read an XML document using the functions you get when you create a model of the XML document in TransacXML.
Note that before you can read an XML document using TransacXML, you must model the document in the Plex model.
The following document describes how you can read an XML document that is stored in a file.
The same method is used if you want to read an XML document when you are implementing web services. The only difference is the inheritance of the import function.
When you want to read information from an XML document, you actually have to do two different things:
When navigating the document it is important to understand the tree-structure of the document you are working with.
TransacXML offers different ways of handling these two tasks:
- Using the TraverseAndFetch functions
This is a highly automated method, where the functions automatically traverse the XML document and read the information it contains.
Each XMLElement that is defined in the document scopes a function called TraverseAndFetch. Each of these functions will be called once for each instance of the XMLElement that is present in the document. The TraverseAndFetch function reads the information that is defined as fields in the TransacXML model is read and places the data in a local variable called View.
- Using the GetFirstOccurrence, ProcessGroup, and SingleFetch functions.
When using these functions, you will code the navigation in the tree-structure manually.
GetFirstOccurrence is used to find single-occurrence complex elements in the document.
ProcessGroup is used to traverse through repeating complex elements.
SingleFetch is used to read the data based on the element identification that has been retrieved by GetFirstOccurrence/ProcessGroup.
Choosing between these two methods will often come down to a question of personal preference for one programming style over another. But there are some points you can use to choose which method to choose.
It is recommended that you try both approaches so that you can make the best decision for your real-life tasks.
This document describes functionality to traverse the entire document and to read all of the information.
In some cases, you might process a document where you only want to retrieve information from a small part of the document.
This is complicated to describe as an abstract case. So instead of trying to do so, the last two examples in this document show two different ways to retrieve data from a part of a document without having to traverse the entire document.
No matter which method you want to use for reading the document, you need an import function to initialize the XML-environment. This function also loads the document from the file and generates the tree-structure used to process the document.
Import functions are created by inheritance from ImportXMLDocument:
| Source Object | Verb | Target Object |
|---|---|---|
| MyImportFunction | is a FNC | ImportXMLDocument |
The function will have the following interface:
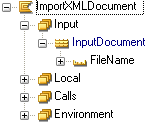
The input parameter allows you to specify where the file you want to read is stored (path and name).
The local variable "InputDocument" contains two fields that are extensively used when calling TransacXML functions. You can see these fields as being an alias for the XML document you are reading.
The ImportXMLDocument creates a memory store where all of the XML-objects that is created as you read the document can be stored. The identification of this store is available at:
Local/InputDocument<ObjectStoreReference>
It also creates a parser-document (an object stored in memory into which the tree-structure the parser generates based on the XML-file is loaded). The identification of this parser-document is available at:
Local/InputDocument<ObjectDocument>
Using the TraverseAndFetch functions is very easy. You only need to insert a call to the TraverseAndFetch function scoped by the top element of the document - and the rest of the handling of the XML document happens automatically.
The interface of a TraverseAndFetch function contains two fields:
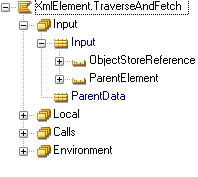
1. An ObjectStoreReference - always map with Local/InputDocument<ObjectStoreReference>
2. A ParentElement - specify Local/InputDocument<ObjectDocument> when calling the TraverseAndFetch function for the top element
The other input variable ParentData is empty - but you can add fields to it if you want to transfer fields from the calling TraverseAndFetch function (The automatically generated call will map this with values from the local variable View and the input variable ParentData in the calling TraverseAndFetch function).
The TraverseAndFetch function has three tasks, which it performs automatically:
In this way, the TraverseAndFetch function will go through all instances of the scoping XMLElement in the document. For each instance it will read the data and call the TraverseAndFetch functions of the complex child elements.
The TraverseAndFetch function contains an edit point "Handle element". This edit point will be reached once for each occurrence of the scoping XMLElement found in the document that is being read. In this edit point, you can access the data from the current complex element in the local variable "View".
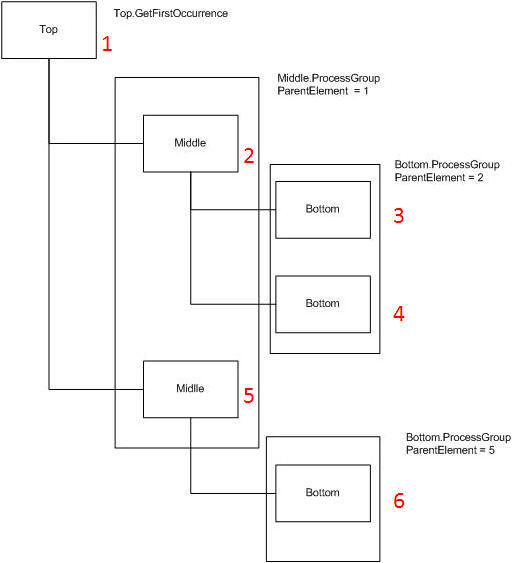
The order the TraverseAndFetch functions will process a document can be exemplified as follows:
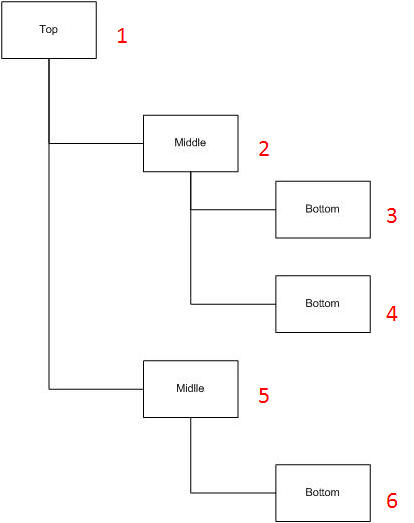
The function Top.TraverseAndFetch is called from the import program.
Top.TraverseAndFetch reads the simple elements and attributes from the "Top" element (1).
Then it calls Middle.TraverseAndFetch.
Middle.TraverseAndFetch finds the first occurrence of the "Middle" element (2) and reads the simple elements and attributes from this element.
Then it calls Bottom.TraverseAndFetch (specifying the identification of the element marked "2" as Parent Element).
Bottom.TraverseAndFetch finds the first "Bottom" child element (3) and reads the simple elements and attributes for this element.
Then it finds the next "Bottom" child element (4) and reads the simple elements and attributes for this element.
Finally it terminates and returns control to Middle.TraverseAndFetch.
Middle.TraverseAndFetch finds the next occurrence of "Middle" (5) and reads the simple elements and attributes for this element.
Then it calls Bottom.TraverseAndFetch (specifying the identification of the element marked "5" as Parent Element).
Bottom.TraverseAndFetch finds the first (and only) "Bottom" child element (6) and reads the simple elements and attributes for this element.
Then it terminates and returns control to Middle.TraverseAndFetch
Middle.TraverseAndFetch terminates and returns control to Top.TraverseAndFetch.
Top.TraverseAndFetch terminates and returns control to the import function.
Due to the automatic calls made by the TraverseAndFetch functions, you can't create inherited functions based on TraverseAndFetch functions. You have to enter your code in the basic TraverseAndFetch functions themselves.
The TraverseAndFetch functionality only works if there are ENT includes ENT triples for each scoped XMLElement entity.
This is the alternative to using the TraverseAndFetch functions.
When using these function types, you will have to manually code the navigation of the document tree-structure.
The navigation is performed using the GetFirstOccurrence and ProcessGroup functions.
For each complex element you reach, you must call the corresponding SingleFetch function to retrieve the data.
The function finds the first occurrence of the scoping XMLElement in the document - either in the entire document or the first occurrence that is the child of a specific complex element (ParentElement).
These functions have the following interface:
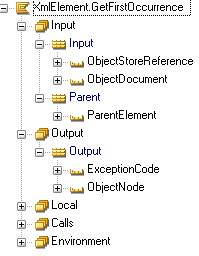
In the following structure this means that if you call Bottom.GetFirstOccurrence and specify NULL for the Parent Element, it will find the indicated element.
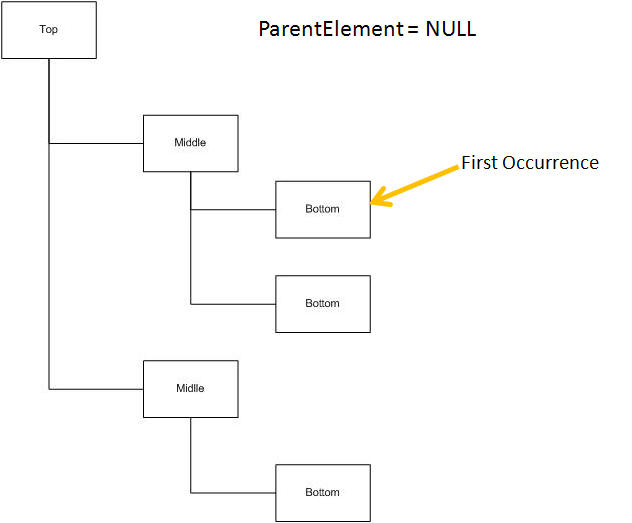
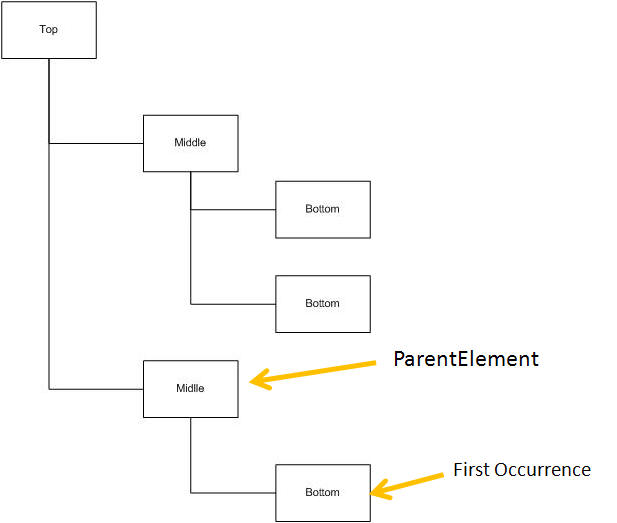
If you specify the identification of the second occurrence of "Middle" as the ParentElement, you will find the element indicated here:
The ProcessGroup function is used to traverse all the instances of a complex element under a specific parent element.
Note that only entities inheriting from XMLRepeatingElement get a scoped ProcessGroup function.
In general, you should not call the basic ProcessGroup directly, instead create you own version by inheriting from the basic ProcessGroup and use this function in your functionality.
When calling a ProcessGroup, you must specify two parameters:

When calling the ProcessGroup from an ImportXMLDocument function, always map with Local/InputDocument<ObjectStoreReference>, when calling from another ProcessGroup, map with Local/CurrentElement<ObjectElement>
So if you in the following structure calls Bottom.ProcessGroup, and specify the first occurrence of "Middle" as the Parent Element, it will first find the "Bottom" element marked "1" - and then the one marked "2".
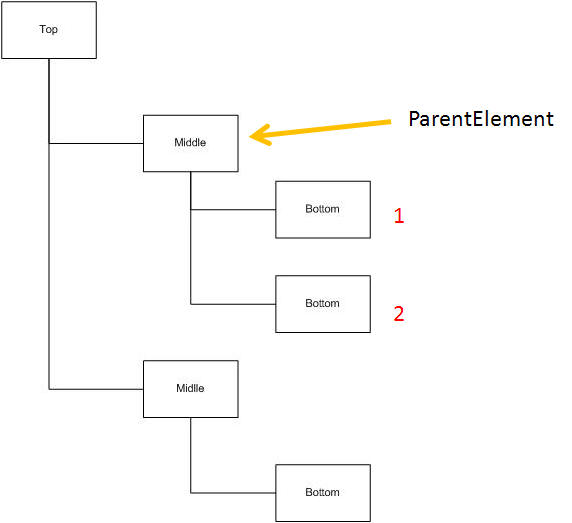
Note that the ProcessGroup only performs navigation in the tree - it does not read any data.
The ProcessGroup contains an edit point "Process Element". This edit point will be reached once for each occurrence of the scoping XMLElement that is a child element of the parent element specified in the input parameter.
The local variable CurrentElement contains a field "ObjectElement" that is the reference to the current complex element. This can be used as input parameter for the SingleFetch function or as the ParentElement parameter for calling GetFirstOccurrence/ProcessGroup functions for the child elements of the current element.
The SingleFetch function retrieves the data from a specific complex element. It retrieves all of the simple elements and attributes that is defined in the Plex model and places the values in the output variable "Data".
When you call the SingleFetch function, you must specify two input parameters:
You traverse and extract values from the entire document in this way:
1a. Call the GetFirstOccurrence function for the top element. Specify NULL for the ParentElement parameter. Set the current element to the output from the GetFirstOccurrence
1b. Call the SingleFetch function for the top element (retrieve the data).
2. For each single-occurrence complex child element of the current element:
2.a. Call the GetFirstOccurrence function, specifying the current element as the ParentElement parameter.
2.b. For each of these calls that return an element, call the SingleFetch function.
2.c. For each of these calls that return an element perform - set current element to the element returned by the GetFirstOccurrence function and perform step 2/3 (recursively)
3. For each multi-occurrence complex child element (XMLRepeatingElement entity in Plex):
3.a Call the ProcessGroup function, specify the current element as the ObjectElement parameter.
3.b. In the ProcessGroup, edit point "Process element", call the SingleFetch
3.c. For each element perform step 2/3 (recursively).
In this way the following structure will be traversed and read as described below:
In the import function (edit point Process Xml document):
1. Call Top.GetFirstOccurrence
2. Call Top.SingleFetch
3. Call Middle.ProcessGroup (specify the output from Top.GetFirstOccurrence for the ObjectElement parameter).
In Middle.ProcessGroup (edit point Process element):
- Call Middle.SingleFetch (ObjectElement parameter = Local/CurrentElement<ObjectElement>).
- Call Bottom.ProcessGroup (specify Local/CurrentElement<ObjectElement> for the ObjectElement parameter).
In Bottom.ProcessGroup (edit point "Process element):
- Call Bottom.SingleFetch (ObjectElement parameter = Local/CurrentElement<ObjectElement>).
This code will traverse and fetch the document in the order shown on the diagram.
As in any other program, you should check whether the called function reports any errors. Like most other Plex functions, you do this by checking the *Returned status after each call. This states whether the call has been successful - but does not state anything about the cause of the error.
In some cases the TransacXML runtime has been able to gather more information about the error. If this information is present, it has been stored in a stack of error-messages.
You can retrieve the information from the stack by calling the function DomServices.ErrorPop repeatedly (as long as the output parameter ExceptionCode2 is successful).
This retrieves the errors from the stack.
The following examples will show how you can read the following document:
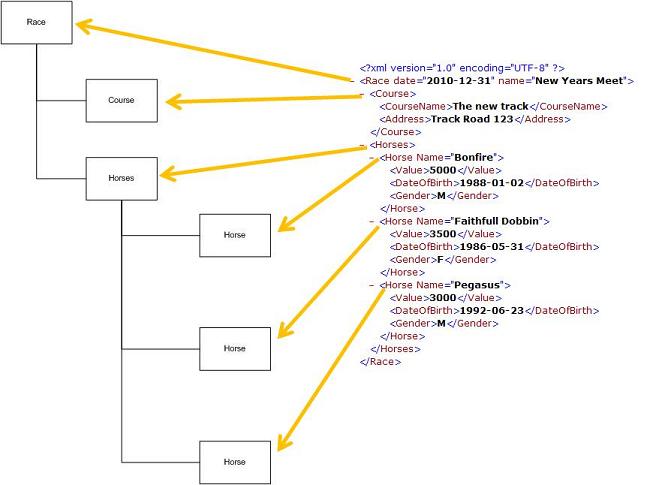
Before reading the document, you need to model in the Plex model.
The first two examples will traverse the entire document using the two methods described above. The last two examples show how you can access specific information in the document without having to traverse the entire content.
In all 4 examples the retrieved data will be shown by dialog messages. In a normal application, these locations are where you have to handle or store the information.
Create the dialog messages: RaceData, CourseData, and HorseData and specify the following parameters for the messages:
| Source Object | Verb | Target Object |
|---|---|---|
| RaceData | parameter FLD | Race.Fields.date |
| RaceData | parameter FLD | Race.Fields.name |
| CourseData | parameter FLD | Race.Course.Fields.CourseName |
| CourseData | parameter FLD | Race.Course.Fields.Address |
| HorseData | parameter FLD | Race.Horses.Horse.Fields.Name |
| HorseData | parameter FLD | Race.Horses.Horse.Fields.Value |
| HorseData | parameter FLD | Race.Horses.Horse.Fields.DateOfBirth |
| HorseData | parameter FLD | Race.Horses.Horse.Fields.Gender |
And specify the following literals for the messages:
RaceData
Race
date: &(1:)
name: &(2:)
CourseData
Course
CourseName: &(1:)
Address: &(2:)
HorseData
Horse
Name: &(1:)
Value: &(2:)
DateOfBirth: &(3:)
Gender: &(4:)
This example shows how you can use the TraverseAndFetch functions to read all information from the document. The functions will traverse the document in the following order:
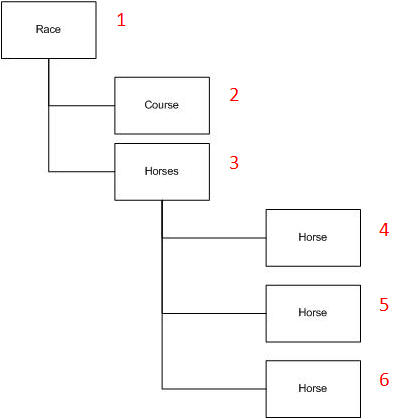
The full functionality of each function is:
So in each TraverseAndFetch function, the data for each of the instances of the scoping XMLElement will be available (in the local variable View).
You need to call the Race.TraverseAndFetch function from an import function. This is created by the triple:
| Source Object | Verb | Target Object |
|---|---|---|
| ReadHorseXML_TraverseAndFetch | is a FNC | ImportXmlDocument |
In the edit point "Process XML document", enter the following code:
Call Race.TraverseAndFetch
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
In Race.TraverseAndFetch - edit point "Handle element", show the dialog message RaceData, map with the values in the View variable:
Dialog Message Message: RaceData
Map with:
View<Race.Fields.date>
View<Race.Fields.name>
In Race.Course.TraverseAndFetch - edit point "Handle element", show the dialog message CourseData, map with the values in the View variable:
Dialog Message Message: CourseData
Map with:
View<Race.Course.Fields.CourseName>
View<Race.Course.Fields.Address>
In Race.Course.TraverseAndFetch - edit point "Handle element", show the dialog message HorseData, map with the values in the View variable:
Dialog Message Message: HorseData
Map with:
View<Race.Horses.Horse.Fields.Name>
View<Race.Horses.Horse.Fields.Value>
View<Race.Horses.Horse.Fields.DateOfBirth>
View<Race.Horses.Horse.Fields.Gender>
If you run this program, you will see that the document is traversed in the order described above - and that the data is available in the View variable of each TraverseAndFetch function.
Note that the only XML-related code, you had to do was to call the Race.TraverseAndFetch function in your import function.
In this example you will traverse and read the document in the exact same order as in the TraverseAndFetch example above. The difference is that where TraverseAndFetch handles all the navigation and retrieval of data automatically, you will have to code this function yourself.
The document is traversed using the following functions - for each element that contains data (simple elements or attributes) the corresponding SingleFetch function is called to actually retrieve the data:
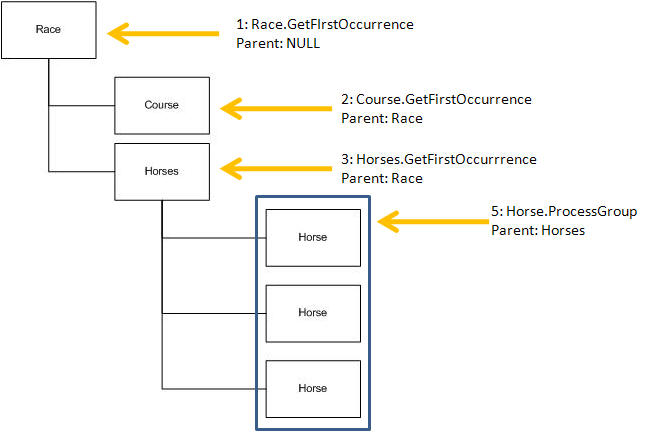
The full functionality of the example is as follows:
As for the TraverseAndFetch example, you need an import function to initialize the XML environment. This is created by the triple:
| Source Object | Verb | Target Object |
|---|---|---|
| ReadHorseXML_Functions | is a FNC | ImportXmlDocument |
As for standard Plex ProcessGroup functions scoped by the views of the relational entities, you should not use the abstract ProcessGroup itself, instead create a specific version of the ProcessGroup function for each usage.
Create a new ProcessGroup function for the Horse entity by creating the triple:
| Source Object | Verb | Target Object |
|---|---|---|
| Race.Horses.Horse.ReadHorsesProcessGroup | is a FNC | Race.Horses.Horse.ProcessGroup |
| Race.Horses.Horse.ReadHorsesProcessGroup | implement SYS | Yes |
This function will be used to traverse the Horse elements.
In the import function - edit point "Process XML document", enter the following code:
Call Race.GetFirstOccurrence
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
<ParentElement.NULL>
If Environment<*Returned status> == <*Returned status.*Successful>
Call Race.SingleFetch
Map with:
Local/InputDocument<ObjectStoreReference>
Race.GetFirstOccurrence/Output<ObjectNode>
If Environment<*Returned status> == <*Returned status.*Successful>
Dialog Message Message: RaceData
Map with:
Race.SingleFetch/Data<Race.Fields.date>
Race.SingleFetch/Data<Race.Fields.name>
Call Race.Course.GetFirstOccurrence
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
Race.GetFirstOccurrence/Output<ObjectNode>
If Environment<*Returned status> ==
<*Returned status.*Successful>
Call Race.Course.SingleFetch
Map with:
Local/InputDocument<ObjectStoreReference>
Race.Course.GetFirstOccurrence/Output<ObjectNode>
If Environment<*Returned status> == <*Returned status.*Successful>
Dialog Message Message: CourseData
Map with:
Race.Course.SingleFetch/Data<Race.Course.Fields.CourseName>
Race.Course.SingleFetch/Data<Race.Course.Fields.Address>
Call Race.Horses.GetFirstOccurrence
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
Race.GetFirstOccurrence/Output<ObjectNode>
If Environment<*Returned status> == <*Returned status.*Successful>
Call Race.Horses.Horse.ReadHorsesProcessGroup
Map with:
Local/InputDocument<ObjectStoreReference>
Race.Horses.GetFirstOccurrence/Output<ObjectNode>
In Race.Horses.Horse.ReadHorseProcessGrup - edit point "Process element" enter the following code:
Call Race.Horses.Horse.SingleFetch
Map with:
Input<ObjectStoreReference>
CurrentElement<ObjectElement>
If Environment<*Returned status> == <*Returned status.*Successful>
Dialog Message Message: HorseData
Map with:
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Name>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Value>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.DateOfBirth>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Gender>
This example shows how you can go directly to a sub element in the document without traversing the top part of the document.
This example will show how you can go directly to the Course element without reading the Race element.
A GetFirstOccurrence function where you do not specify a value for the ParentElement will find the first occurrence of the element in the document.
So in this case, you will just call the Course.GetFirstOccurrence function to find the Course element (specify NULL for the ParentElement) - and then call the Course.SingleFetch to retrieve the data.
Create the import function by creating the triple:
| Source Object | Verb | Target Object |
|---|---|---|
| ReadHorseXML_Course | is a FNC | ImportXmlDocument |
In the edit point "Process XML document", enter the following code:
Call Race.Course.GetFirstOccurrence
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
<ParentElement.NULL>
If Environment<*Returned status> == <*Returned
status.*Successful>
Call Race.Course.SingleFetch
Map with:
Local/InputDocument<ObjectStoreReference>
Race.Course.GetFirstOccurrence/Output<ObjectNode>
If Environment<*Returned status> == <*Returned status.*Successful>
Dialog Message Message: CourseData
Map with:
Race.Course.SingleFetch/Data<Race.Course.Fields.CourseName>
Race.Course.SingleFetch/Data<Race.Course.Fields.Address>
Example 3 shows how you can retrieve the first occurrence of a specific complex element in a document. But in some cases you need to retrieve a specific instance of a complex element instead of the first one. This example will show how you can retrieve information for a specific Horse without traversing the rest of the document.
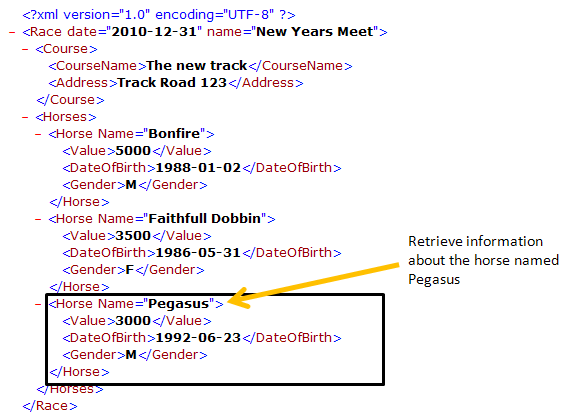
The GetFirstOccurrence function uses XPath expressions to find the first occurrence of the complex element. This is the feature that you can use to find a specific instance of the complex element instead of the first one.
You will probably need some understanding of the XPath-syntax to be able to specify the element to retrieve.
Create the import function by creating the triple:
| Source Object | Verb | Target Object |
|---|---|---|
| ReadHorseXML_ByHorseName | is a FNC | ImportXmlDocument |
Create a version of GetFirstOccurrence that can be used to find a specific horse - and a message which can be used to generate the XPath expression:
| Source Object | Verb | Target Object |
|---|---|---|
| Race.Horses.Horse.GetHorseByName | is a FNC | Race.Horses.Horse.GetFirstOccurrence |
| Race.Horses.Horse.GetHorseByName | variable VAR
...as SYS |
Select
Input |
| Race.Horses.Horse.GetHorseByName | input FLD
...for VAR |
Race.Horses.Horse.Fields.Name
Select |
| Race.Horses.Horse.GetHorseByName | local FLD
...for VAR |
XPathExpression
Local |
| Race.Horses.Horse.GetHorseByName | message MSG | XPath |
| Race.Horses.Horse.GetHorseByName.XPath | parameter FLD | Race.Horses.Horse.Fields.Name |
Specify the following literal for the XPath message:
[@Name="&(1:)"]
This is an XPath predicate, that when you add it to the auto-generated XPath expression used by the GetFirstOccurrence function, will select the Horse element that has an attribute "Name" with the value specified by the Name parameter. If there is more than one Horse element with the specified name, the first one will be selected.
In Race.Horses.Horse.GetHorseByName (edit point Before selectSingleNode) add the following code:
Format Message Message: Race.Horses.Horse.GetHorseByName.XPath, Local<XPathExpression>
Map with:
Select<Race.Horses.Horse.Fields.Name>
Set Work<XPathExpression> = Work<XPathExpression> CONCAT Local<XPathExpression>
In this way, the predicate defined in the message is added to the "standard" XPath expression used by the GetFirstOccurrence function.
As an example, the following XPath expression will be generated if you specify "Pegasus" for the Name attribute and NULL for the ParentElement parameter:
Race/Horses/Horse[@Name="Pegasus"]
In the import function (edit point Process XML document), enter the following code:
Call Race.Horses.Horse.GetHorseByName
Map with:
Local/InputDocument<ObjectStoreReference>
Local/InputDocument<ObjectDocument>
<ParentElement.NULL>
The name of the horse to find.
If Environment<*Returned status> == <*Returned status.*Successful>
Call Race.Horses.Horse.SingleFetch
Map with:
Local/InputDocument<ObjectStoreReference>
Race.Horses.Horse.GetHorseByName/Output<ObjectNode>
If Environment<*Returned status> == <*Returned status.*Successful>
Dialog Message Message: HorseData
Map with:
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Name>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Value>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.DateOfBirth>
Race.Horses.Horse.SingleFetch/Data<Race.Horses.Horse.Fields.Gender>
Note that this function ONLY works when the ParentElement parameter is set to NULL. If you specify the parent element, the GetFirstOccurrence function uses some more efficient ways to retrieve the data - which means that the specified edit point is not even reached.
In the above example a predicate is added to the default XPath expression. In some cases, you want to have full control of the XPath expression. In these cases just overwrite the Work<XPathExpression> field instead of adding information to it.
Most examples of XPath syntax ignore namespaces - or handle them by using the prefix assigned to the namespace in the document.
If you specify an XPath expression that does not specify namespaces on a document where namespaces is used, the GetFirstOccurrence function will not find any elements.
The syntax for specifying that an element belongs to a namespace is as follows:
*[local-name()="..." and namespace-uri()="..."]
So if the Race element belongs to the namespace http://www.websydian/examples/race - you would have to specify:
*[local-name()="Race" and namespace-uri()="http://www.websydian/examples/race"] instead of just specifying Race in the XPath expression.
The TransacXML functions all set the field Environment<*Returned status>.
In the cases where the status is not successful, you will often want more information about the error. The following document describes how the TransacXML runtime stores any errors it detects and how you can retrieve them.
More information about TraverseAndFetch
More information about modeling, creating and processing XML