|
|
Introduction Implementing Other Uses Parts Tutorial Glossary
The XmlElement entity is an abstract entity from which certain entities in the XML model structure inherit. The entities inheriting from XmlElement are those which reflect elements that can occur at most once at a given level in the XML document. Among others, XmlElement scopes two functions, SingleFetch and FlatView, which are used to retrieve data from XML documents.
When modeling an XML document in Plex, an XML element corresponds to a single instance complex element.
See also XmlRepeatingElement below.
The behavior of both XmlElement and XmlRepeatingElement are controlled by a number of options. These options are set on the function ElementOptions.
The GetFirstOccurrence function is a service function that returns the first occurrence of the scoping XmlElement within the scope of a parent element. GetFirstOccurrence effectively eliminates the need to perform advanced DOM processing of the document in the case where the first occurrence of an element is wanted.
The parameter list can be seen in the table below.
| Type | Variable | Field | Descripton |
| Input | Input | ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ObjectDocument | Reference to the document element which this function should operate on. | ||
| Parent | ParentElement | The parent element where the search should start.
If this element is null the first occurrence within the entire document is returned. If a value is specified for this parameter, only complex elements that are immediate child elements of the specified parent element will be returned. |
|
| Output | Output | ObjectNode | The first occurrence found. If no element is found the returned reference is Null. |
| ExceptionCode | If an error occurred this field will contain the error code. |
The GetFirstOccurrence function validates a number of things concerning the input parameters, we have found that this have some influence on the performance if very large documents are processed. The validation can be disabled by setting the function option ValidateInput to No.
This function is used to hold the options determining basic behavior of the functions scoped by the parent XmlElement.
The table below describes the options that are available, their default value, as well as what the options control.
| Option | Default Value | Description |
|---|---|---|
| UseInheritanceForFields | Yes | This option allows the developer to override the default
behavior of TransacXML with respect to field definitions.
Per default, TransacXML uses the inheritance of the fields to determine whether the field is an attribute in the XML document, a simple element, or a repeating simple element. If the inheritance option is set to no, all fields are handled as if they were simple elements. This way it is possible to reuse existing fields without changing them. This makes it possible to make XML representations of existing database fields without making modifications to the database records. Note that this option introduces a potential
problem when reading documents.
The data retrieved from the document is represented as character strings. These strings are used to populate the output, which can be e.g. date or numeric fields.
If the data from the document is not actually valid according to the data type of the result field, unexpected behavior occurs.
One example, which we have seen in the Java implementation is that the (invalid) date "2009-02-29" is converted to "2009-03-01" when cast to a DateISO field.
So if you want to use this option when reading documents, you need to be certain that the data in the document is valid for the fields you map to. |
| UseImplementationNameForFields | No | This option allows the developer to override the default
behavior of TransacXML with respect to the representation of fields
in XML documents.
Per default, TransacXML uses the model name of the field, or the value in the LongName source code if the field is inheriting from LongName. The UseImplementationNameForFields option allows the developer to specify that the implementation name of the field should be used instead. This is useful when working with existing fields that cannot be modified, and when the fields have names that the developer will not use (e.g. names that are illegal accordingly to the XML specification). |
| Optional | No | This option allows the developer to specify whether or not the
element scoping the ElementOptions function are considered optional
or mandatory.
This option is different from the other options in the sense that it impacts the element itself, not the fields referred to by the element. The only direct impact of this option is the way the DTD is generated (please refer to the Implementation Guide for more information on DTD's). |
The SingleFetch function is used to retrieve data from an XML element with a combination of attributes and simple elements. This function provides the Websydian developer with a relational view of the XML element whose data is to be retrieved. Using the SingleFetch function, the XML element's data can be viewed as a row from a relational database table.
The relational SingleFetch function uses a key to fetch data. The TransacXML SingleFetch function requires an ObjectReference to the XML element containing the data. The ObjectReference to the relevant XML element can be obtained by using the GetFirstOccurrence function, or alternatively - for more advanced processing - the DOM function selectSingleNode, which is part of the WSYDOM Function Suite.
The output parameter NextOccurrence points to the next occurrence of the element fetched. If no such element exists NextOccurrence is Null.
NextOccurrence is useful when working with repeating elements, and saves the developer from having to use DOM functions in order to get the next occurrence of an element.
NextOccurrence finds occurrences of an element only within the same context as the element fetched by SingleFetch. This means that only siblings are found - not occurrences elsewhere in the document.
From version 6.1.2, NextOccurrence, the retrieval of the NextOccurrence value is controlled by a function option GetNextOccurrence - see more information below.
The SingleFetch function validates a number of things. It validates whether the node specified in the input is an element node, whether the name of the node corresponds to the one defined in the model and whether the namespace is correct.
This validation does carry a performance overhead. Set the function option ValidateInput to No if you want to enhance the performance.
As part of a performance investigation we have found that in large documents, the retrieval of the NextOccurrence value in some instances can be a significant part of the processing time of the SingleFetch function. To avoid this overhead a function option GetNextOccurrence has been introduced. If the value of this option is set to No, the NextOccurrence field will always return 0.
As there are relatively few cases where the NextOccurrence really gives any meaning - and as we have found that the overhead occurs even if there are no next occurrence to retrieve, we have selected to set the default value of this option to No. This means that if you want to have the NextOccurence functionality for a SingleFetch function - you have to set the function option to Yes.
This option is only relevant for Java functions.
The option is only relevant if the GetNextOccurence option is set to Yes.
Set the option to Yes if no other elements are placed between the elements you want to get the NextOccurrence for - as the element B in this example:

This limits the performance overhead of the NextOccurrence functionality (in some cases significantly).
If there are other elements placed between the recurring elements you want to read - as in the next example where a C element is placed between the B elements - you should set the option to No.
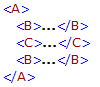
Note that if you have a document where the last instance of the element you want to retrieve using the NextOccurrence feature is followed by many sibling elements, you should ensure that you set the OnlySequencedNextOccurrences to Yes if you set the GetNextOccurence option to yes.
For instance if you in a document like this want to read B using the Next Occurrence feature:

Note that if you let your XMLElement entity inherit from XMLRepeatingElement, you can always use the scoped ProcessGroup to retrieve the elements.
Another option is to use TraverseAndFetch to process the document.
The FlatView function is an abstract function used to retrieve data from an XML element and its descendants. Using the FlatView function is equivalent to implementing a series of different SingleFetch calls. Thus, the FlatView function offers a convenient way of retrieving data from different levels of the XML document. From a relational point of view, using FlatView corresponds to fetching rows from multiple tables between which a one-to-one relation exists.
By default this function is set to implement No so to make use of this function this must be overwritten with a implement Yes triple.
The FieldHolder function is an abstract function which serves as the ancestor of functions that inherit from the FlatView function.
FieldHolder is an internal service function not intended for direct use.
The Fields function is used as a placeholder for the fields created in the XML modeling process. We recommend using Fields to scope the fields as specified in the implementation guide, as this preserves the model-based approach and documents the XML structure in the CA Plex model.
However, the functionality of TransacXML is unchanged if for some reason this approach is not chosen.
InsertRowDangling creates a row with the Proximity Nodes specified in the Data view. The created row is not attached to the document but merely exists as a dangling tree of DOM objects.
If any of the fields corresponding to Proximity Nodes are assigned Null values, the corresponding Proximity Node is not created. This allows the handling of optional elements.
InsertRowDangling has been supplied in order to give the application developer exact control of where to attach a row (differently from InsertRow, that per default attaches the row as the last child of the ParentElement, see InsertRow).
InsertRowDangling returns a reference to the root of the element tree created.
| XML Example |
|---|
|
<Orders> |
Suppose a new OrderLine is to be inserted in the XML document. Calling InsertRowDangling would result in DOM objects reflecting the following element tree being created:
| XML Example |
|---|
|
<OrderLine> |
By calling InsertRowDangling, the relevant tree of objects is created but is not attached to any of the objects in the document tree. From a relational point of view, an OrderLine should always be connected to a particular Order (as the primary key for Order most likely is part of the primary key for OrderLine).
InsertRowDangling does not connect the OrderLine to a particular Order, it merely creates the OrderLine. By calling InsertRow instead of InsertRowDangling, the OrderLine can be created and attached to the relevant Order in one operation.
The rationale behind including the atomic InsertRowDangling function (operation) is that in some cases, it may be undesirable to attach an element tree reflecting a relational row as the last child of an element (as InsertRow does).
Using InsertRowDangling, the application developer can decide where to insert the element, if at all. After a call to InsertRowDangling the application developer can use the DOM functions in WSYDOM to attach the created element tree wherever he sees fit.
If a field in the Data view is a repeating element field then code must be inserted in order to insert multiple instances of the same simple element. By default the InsertRowDangling function will insert the first instance only (if a value is specified in the field).
To insert more than one instance of a repeating simple element use the following edit points:
InsertRow inherits from InsertRowDangling and in addition to creating the row InsertRow also attaches the row to the ParentElement as the last child
If any of the fields corresponding to Proximity Nodes are assigned Null values, the corresponding Proximity Node is not created. This allows the handling of optional elements.
In some cases you want to ensure that an element or an attribute is created even though the value for the field is the null value defined for the field. The changes necessary to ensure this is described in this FAQ.
InsertRow returns a reference to the root of the element tree attached to ParentElement.
If all Proximity Nodes belonging to a row are Null or no Proximity Nodes are defined for the element, the root element in the row is still created in the DOM representation of the XML document.
In order to insert complex structures, let a function, e.g. MyInsertRow, inherit from the InsertRow function of the root element of the complex structure. In the edit point
Perform DOM processing for complex element
insert calls to the proper InsertRow functions (or proper MyInsertRow functions, if the structure has more nested levels).
See an example of the insertion of an OrderLine row in the description of InsertRowDangling.
Please note that code must be inserted if any of the Proximity Nodes are repeating simple elements. Look here for details.
As default, the InsertRow function validates whether the parent, which the element is attached to, is the one defined in the XML model in Plex. This is a help to ensure that the resulting XML document corresponds to the definitions.
The validation does result in a noticable performance degradation, which can be a problem when creating large documents. To avoid the validation set the function option ValidateInput to No.
UpdateRow updates the values in the Proximity Nodes belonging to RowToUpdate with the values in Data.
UpdateRow handles optional elements by deleting Proximity Nodes if their corresponding field value is Null (in the Data view), and creating/updating Proximity Nodes if their corresponding field value is different from Null.
Note that this means that if you create a special version of the UpdateRow function that only updates a subset of the fields of the XMLElement, you need to also create a special version of the DeleteProximityNodes function that also only handles this subset - and you need to replace with this function on your special UpdateRow function.
| Type | Variable | Field | Description |
|---|---|---|---|
| Input | Input | ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ObjectDocument | Reference to the document where the instance to be updated exist. | ||
| ObjectElement | Reference to the element holding the simple elements to be updated. | ||
| Data | XMLElementData | The data value of the simple element to update. | |
| Output | Output | NextOccurrence | Reference to the next occurrence of the object element. |
By default this function is set to implement No so to make use of this function this must be overwritten with a implement Yes triple.
Detaches and deletes the element tree having the element given in RowToDelete as its root node. Only Proximity Nodes of the RowToDelete element are deleted, whereas descendant Complex Elements are not deleted automatically.
The deletion of such elements is left for a later garbage collection which should be carried out manually by the application developer through e.g. recursive use of DeleteRow or alternatively through the means of the DOM functions available in WSYDOM.
| XML Example |
|---|
|
<Orders> |
When calling DeleteRow with a reference to the above Order element, the following happens:
The OrderLine elements and their descendants (i.e. the Complex Elements) are left undeleted.
Albeit the element trees having the Order element as their parent are left undeleted, they will not be included in an XML document which is generated at a later point in the execution process. This is because they have been detached from the document tree as part of the deletion process.
Dangling elements still exist in memory, but are removed from the document structure. Garbage collection must be taken care of by the application developer.
Thus, performing a DeleteRow operation on an element which has multiple generations of descendants will actually delete the corresponding descendant rows from the "database", but the object representation of such "rows" will still be present in memory.
Modeling the above XML document except as a relational database would yield the two entities Order and OrderLine with a one-to-many relation between Order and OrderLine. Semantically, when deleting a row in the Order table using TransacXML DeleteRow, OrderLine rows referencing that Order row are also deleted from the database. However, the representation of such OrderLine rows is not deleted, but is considered garbage data in the database.
Service function scoped under DeleteRow. DeleteProximityNodes deletes the Proximity Nodes only, leaving the parent node and scoped Complex Elements untouched.
The TraverseAndFetch function scoped under the XMLElement offers a fully automated traversal and retrieval of data for an XML document defined in Plex.
The TraverseAndFetch functions navigates through the document ensuring that each complex element is processed and the data contained in the element is fetched.
This leaves the developer free to focus on the business logic required to handle the received data.
In the Edit point "Handle Element" the data for the current element is present in the local variable View. This is where the handling of the received data should be placed.
Please note that the function only retrieves the elements and data defined in the XML model in Plex. If the document contains data, which is not defined in the XML model, the data will be disregarded.
For details concerning the implementation of the TraverseAndFetch functionality see here.
The XMLShell function is the abstract function, which all of the XML handling functions inherit from.
In some instances it is desirable to make a change, which influences all of these functions. In this case it should be considered whether it is possible to make the change to the XMLShell instead of in each of the functions inheriting from it.
The following functions inherit from XMLShell: SingleFetch, InsertRow, InsertRowDangling, InsertRow, DeleteRow, FlatView, GetFirstOccurrence, UpdateRow, TraverseAndFetch.
Through the XMLShell, the XML handling functions inherit a quite comprehensive validation. In some cases performance consideration can lead to a wish for disabling the validation. The XMLShell can be used for this, when the function option ValidateInput to no none of the validation of the input is executed for any of the XML handling functions.
So, when you have tested the handling of the document, you should consider setting the function option ValidateInput to No on an abstract XMLElement.XMLShell function.
The XmlRepeatingElement entity is an abstract entity from which certain entities in the imported document structure inherit. XmlRepeatingElement inherits from XmlElement (see XmlElement above), but also scopes a ProcessGroup function used to retrieve data from elements occurring any number of times.
The entities inheriting from XmlRepeatingElement are those that reflect elements that can occur more than once at a given level in the XML document.
The ProcessGroup function is an abstract function. It is used to process one at the time elements which can occur more than once at a given level in the XML document.
To process such repeating elements, let a function MyProcessGroup inherit from ProcessGroup.
The function inheriting from ProcessGroup should be scoped to the same entity as the actual ProcessGroup function.
Refer to the Tutorial for a detailed description of how to use the ProcessGroup function.
By default this function is set to implement No so to make use of this function this must be overwritten with a implement Yes triple.
The LongName entity is used when the length of XML element and attribute names exceeds the CA Plex limit of 32 characters. Refer to the Other Uses section and the Implementation Guide for further information on how to handle long names in XML elements and attributes.
The source code LongName scoped to the LongName entity contains the scoping path to the entity which has a name exceeding the 32 character limit of CA Plex object names. Refer to the Other Uses section and the Implementation Guide for further information on how to handle long names in XML elements and attributes.
For a general introduction to namespaces in TransacXML please refer to this document.
The entity NamespaceAware is used to specify a namespace for a complex element. This is done by letting the complex element inherit from NamespaceAware and then specify the namespace in the scoped source code object named Namespace.
Optionally the prefix to be used can also be specified in the scoped source code object Prefix.
Please refer to the implementation guide for examples.
The source code Namespace scoped to the NamespaceAware entity contains the namespace to be used.
The source code Prefix scoped to the NamespaceAware entity contains the prefix to be used to refer to the namespace.
XMLElementWithServiceFunctions is an abstract entity, which inherits from XMLElement, with the addition of service functions for creating DTDs and W3C schemas.
The CreateDTD function is a service function that constructs a DTD (Document Type Definition) based on the XML structure defined in the model. The CreateDTD function returns a DTD representing the XML structure scoped by the entity scoping the CreateDTD function.
To create a DTD call the CreateDTD function scoped by the XmlElement representing the top element in the document. The resulting DTD can then be handled by the developer, e.g. by saving it to a file.
CreateDTD takes two input parameters: ObjectStoreReference and CreateDtdFields.DtdString. ObjectStoreReference should be mapped with Null, as it is unused. CreateDtdFields.DtdString is a dual field that is used to return the created DTD - the resulting DTD will be appended to the field value. It is highly recommended to initialize the CreateDtdFields.DtdString with Null before calling CreateDTD.
It is necessary that all of the XMLElements, which are part of the document, inherit from XMLElementWithServicefunctions and that all of the scoped CreateDTD functions are generated and built before running the CreateDTD function for the top XMLElement.
For more information on DTD's please refer to the Implementation Guide.
The CreateDTD function is only implemented as a Windows C function. Note that calling more than one CreateDTD from within the same function may cause unpredictable output.
The CreateSchema function is a service function, which creates a file containing a W3C-schema representation of the XML-model with the scoping XMLElement entity as the top element.
The function is generated in the language defined by the variant of the WSYDOM library. The function can be called by running it from the generate and build window or it can be called from another function.
All of the XMLElements that are part of the document, must inherit from XMLElementWithServicefunctions.
All of the scoped CreateSchema functions must be generated and built before running the CreateSchema function for the top XMLElement.
For more information see the Create Schema Guide.
Please note that if you use Java, a special function (StartCreateSchema) has to be used to call the CreateSchema function. You can read more about this in the Create Schema Guide.
The function ExportXMLDocument is a service function providing the framework for creating functions that export information to a XML document. The ExportXMLDocument also provides the framework for doing correct error handling when calling functions of TransacXML.
Inherit from this function, when you want to make a function, which should create and save an XML document.
The input for the ExportXMLDocument function specifies the name of the file the document is saved to, together with the version and encoding to be used when saving the document.
The ExportXMLDocument function performs the necessary initialization of the DOM environment and creates the DOM document object, which is to contain the XML document. The reference to this DOM document object (ObjectStoreReference and ObjectDocument) is stored to the local variable OutputDocument.
The user processing necessary to create the XML document should be placed in the edit point "Process XML Document".
The ExportXMLDocument function finishes by saving the document to the file indicated in the input, after which the memory allocated to the document is released. This means that after the program has terminated, the XML document is no longer loaded in memory and can't be referred by the object references.
The subroutine "Check Error" is called after each function call. The Function terminates if an error occurs.
Please refer to the XML tutorial for examples on how to use this function.
The function ImportXMLDocument is a service function providing the framework for creating functions that read information from an XML document. The ImportXMLDocument also provides framework for doing correct error handling when calling functions of TransacXML.
Inherit from this function, when you want to make a function, which should read/process an XML document.
The input for the ImportXMLDocument function is the name of the file containing the document to be processed.
The ImportXMLDocument makes the necessary initialization of the DOM environment and creates the DOM document object, which is to contain the XML Document. The reference to this DOM document object (ObjectStoreReference and ObjectDocument) is stored to the local variable InputDocument.
After the initialization is done, the function loads the document from the indicated file.
The user processing necessary to process the XML document should be placed in the edit point "Process XML Document".
The ImportXMLDocument finishes by releasing the memory allocated to the document.
The subroutine "Check Error" is called after each function call. The Function terminates if an error occurs.
Please refer to the XML tutorial for examples on how to use this function.
In many cases it is necessary to read a received XML document and create a reply document based on the received data.
The framework for handling this situation is created by making a function, which inherits from both the ImportXMLDocument and ExportXMLDocument functions. In this case two DOM document objects are created. One for the input document, where the reference is stored in the local variable InputDocument and one for the output document, where the reference is stored in the local variable OutputDocument.
The user processing should still be placed in the "Process XML Document".
The TraverseTopFunction function is basically an ImportXMLDocument function. The function acts as the top function for the TraverseAndFetch functions scoped under XMLElement. The function initiates the parser and loads the XML file specified by the input parameter filename.
The function contains a call to the abstract XMLElement.TraverseAndFetch function, which must be replaced by a call to the TraverseAndFetch function scoped by the top element of the document to be processed. In this way the document to be handled is chosen.
For details concerning the implementation of the TraverseTopFunction see here.
A simple element that occurs at most once in the document must inherit from ElementField. Please refer to the Implementation Guide and the Other Uses document for further information.
A simple element that occurs multiple times in the document is called a repeating simple element and must inherit from RepeatingElementField. Please refer to the Implementation Guide for further information.
For an example on how to use RepeatingElementField pleaser refer to this tutorial.
When inheriting from RepeatingElementField the service functions described in the following sections will be scoped to the inheriting field. These functions are used to retrieve and insert data for the repeating simple element.
This function deletes one instance of a repeating simple element. The input parameter list is described in the table below.
| Input Field | Description |
|---|---|
| ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ParentElement | Reference to the parent element for the repeating element instance that should be deleted. |
| ObjectElement | Reference to the repeating simple element instance that should be deleted. |
The element referenced by ParentElement must be a parent to the element referenced by ObjectElement or the function will fail.
This function retrieves the first instance of the repeating simple elements to a given parent element.
| Type | Variable | Field | Description |
|---|---|---|---|
| Input | Input | ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ParentElement | Reference to the parent element for the repeating simple element that should be retrieved. | ||
| Output | Output | ObjectElement | Reference to the first instance of the repeating simple elements or null if no instances exist. |
| Data | RepeatingElementField | If an instance is found this field will contain the data value of the repeating simple element instance. |
Retrieves the next occurrence of a repeating simple element.
| Type | Variable | Field | Description |
|---|---|---|---|
| Input | Input | ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ParentElement | Reference to the parent element for the repeating simple element that should be retrieved. | ||
| PreviousElement | Reference to the previous repeating element. | ||
| Output | Output | ObjectElement | Reference to the next instance of the repeating simple elements or null if the previous element (PreviousElement) was the last element. |
| Data | RepeatingElementField | If an instance is found this field will contain the data value of the repeating simple element instance. |
To obtain a value for the PreviousElement input field use the GetFirst function. The output field ObjectElement (from GetFirst) is then used as input to the the PreviousElement field in the first call to the GetNext function.
GetNext is then repeatedly called and in each iteration PreviousElement is set to the output field ObjectElement from the previous call until a null value is returned.
InsertNext creates and insert a new instance of a repeating simple element. If other instances of the repeating simple element already exists the new element will be inserted after the last occurrence. If no other instances exists the new instance will be inserted after the last element scoped to the parent element (ParentEl ement).
| Type | Variable | Field | Description |
|---|---|---|---|
| Input | Input | ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ObjectDocument | Reference to the document where the new instance should be inserted. | ||
| ParentElement | Reference to the parent element for the repeating simple element that should be inserted. | ||
| Data | RepeatingElementField | The data value of the simple element to insert. | |
| Output | Output | ObjectElement | Reference to the newly inserted simple element. |
As noted above InsertNext assumes that at least one instance of the repeating simple element has been inserted in the document. If this is not the case then please refer to InsertRow for details on how to handle this.
The Process function is used to process all occurrences of a repeating simple element. By default this function is set to implement No, so to make use of this function either override the implement No triple or create a new function that inherits from Process and set this function to implement Yes. The latter method is the preferred way if one needs to implement severeal functions based on Process.
Any function inheriting from Process must be scoped to the same field as the Process function itself.
The input parameter list is described in the table below.
| Input Field | Description |
|---|---|
| ObjectStoreReference | Reference to the object store for the document this function should operate on. |
| ParentElement | Reference to the parent element for the repeating simple elements that should be process. |
To actually process each element use the following edit points:
| Field | Description |
|---|---|
| RepeatingElementField | Contains the data value for the instance currently being processed. |
| ObjectElement | Reference to the current instance for the repeating simple element. |
An attribute in an XML element must inherit from AttributeField. Please refer to the Implementation Guide and the Other Uses document for further information.
The ComplexValue makes it possible to add a text node to a complex element. This makes it possible to create structures like this:
<MyElement>
<SubElement1>123</SubElement>
abcd
<SubElement2>456</SubElement>
</MyElement>
In this case abcd will be modeled as a ComplexValue field.
Another very common structure that ComplexValues are used to model is this:
<MyValue Currency="USD">1000</MyValue>
In this case the amount (1000) is modeled as a ComplexValue field.
The field ComplexElement is used when advanced placement of the elements in the XML document is needed.
TransacXML uses fields and entities to represent the XML document structure, and the order of the triples in the model determines the order of the elements in the document. As it is not possible to mix different types of triples, it is not possible to mix Simple Elements with Complex Elements without a workaround.
The field ComplexElement is used as a dummy field to represent a Complex Element. When a Complex Element must be placed in between Simple Elements a field with the same name as the Complex Element and inheriting from the field ComplexElement is used to represent the Complex Element. When TransacXML encounters a ComplexElement field the pattern searches for a Complex Element with the same name and replaces the field with the Complex Element.
This way it is possible to intersperse different kinds of elements with TransacXML.
Note that the ComplexElement will become a parameter field for your functions (InsertRow, SingleFetch etc.) this can be confusing as this is not a field that has a value - it is only a placeholder for a corresponding complex element. You can remove the field from the parameters of your functions by omitting it from the Data view of the scoping XMLElement.
The source code LongName scoped to the LongName field contains the simple element name exceeding the 32 character limit of CA Plex object names. Refer to the Other Uses section and the Implementation Guide for further information on how to handle long names in XML elements and attributes.
For a general introduction to namespaces in TransacXML please refer to this document.
The field NameSpaceAware is used to specify a namespace for an attribute or a simple element. This is done by letting the attribute/simple element inherit from NamespaceAware and then specify the namespace in the scoped source code object named Namespace.
When using the NameSpaceAware field on attribute fields it is required that a prefix is specified in the scoped source code object Prefix. This is because XML attributes as specified by the XML standard cannot belong to a default namespace.
When using the NameSpaceAware field on simple elements the prefix is optional.
Please refer to the implementation guide for examples.
Attribute fields inheriting from NameSpaceAware must have a prefix specified in the scoped source code object Prefix.